大模型应用开发技术
大语言模型LLM
简介
目前,国内外各家大厂都在训练自己的大模型,没有能力训练的厂家也在开源大模型的基础上微调自己的行业领域大模型。但是,对我们普通人来说,无论是训练还是微调大尺寸的模型(几十上百b参数)所需要的计算资源都是我们无法承受的。所以,只能从应用本身出发,去做一些微小的工作。
在某一细分领域内,进一步提升LLM能力的方法主要有三种:检索增强生成RAG、微调Fine-turning、智能体Agent。下面简单介绍一下这三种方法。
检索增强生成RAG
由于LLM的训练语料是大而全的数据集,所以它在某一细分领域给出的回答往往是不尽如人意的。面对一个专业问题,LLM很有可能答出一个看起来很正确但是完全没有答到真正的要点上的回答。既然如此,那我们就给LLM加上一个专业知识库,遇到专业问题先去知识库里搜索对应内容,再去结合搜索出来的知识进行答案整合和输出。
具体操作步骤是:
- 整理好知识文档,全部提取为文字形式。
- 按照一定的分割规则与长度切分为文本块。
- 使用嵌入模型(embedding model)计算出这些文本块的嵌入向量,并将它们存入向量数据库中。
- 在推理时,计算问题的嵌入向量,使用向量相似性搜索方法从向量数据库中选出与问题最相似的几个文本块,将它们作为context输给LLM作为辅助知识。
微调Fine-turning
第二个方法就是在特定领域的专业数据集上对LLM进行微调,将领域知识融入到模型中。由于全量参数微调所耗费的资源过大,所以一般使用LoRA等方法进行部分参数的微调,降低计算量。微调虽好,但它也有一些缺点:
- 难以构建领域问答对话数据集。
- 数据又增加的情况下,在微调过的模型上再次微调可能效果不佳。
- 容易造成崩溃,使模型丧失正原有的语言能力。
智能体Agent
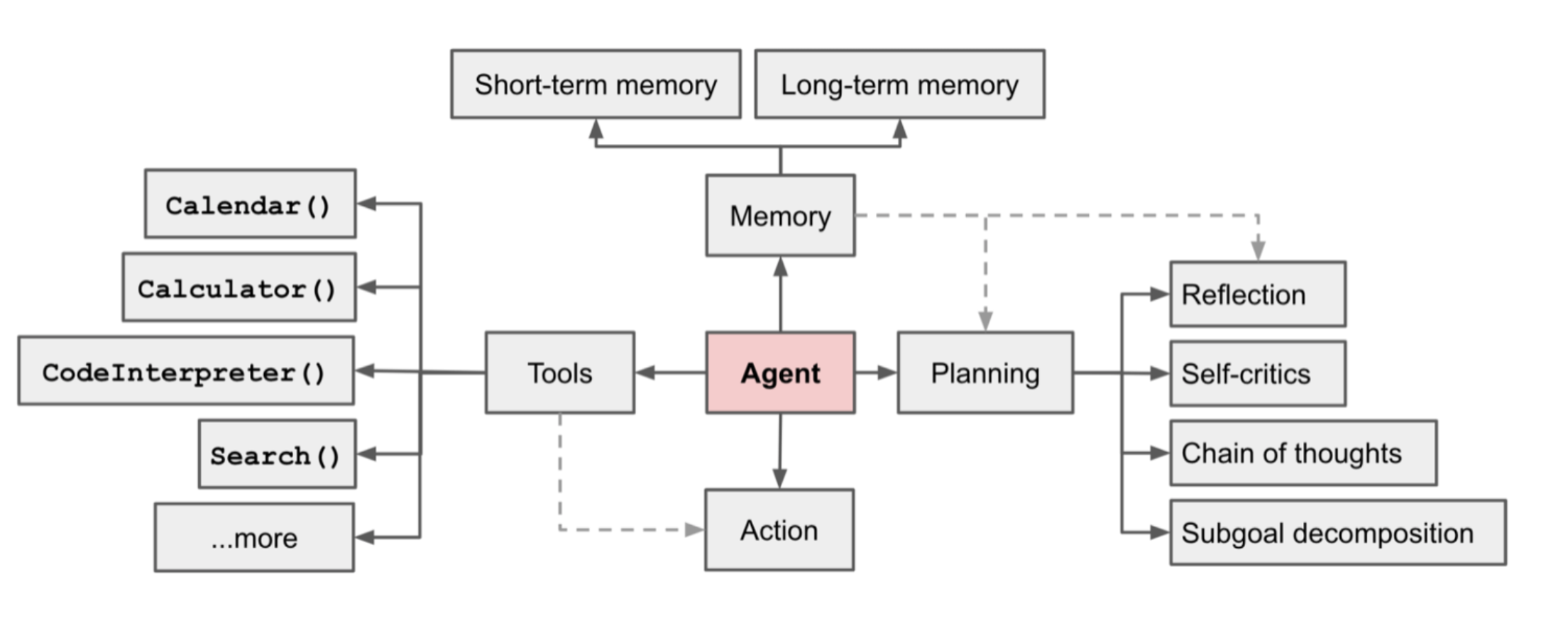
另一个大公司们都在使用的技术路线是智能体。以LLM作为核心,来调用:
- 记忆
- 短期记忆:一轮对话中的历史对话
- 长期记忆:知识库
- 工具
- 函数调用(Function Calling)
- 数据库
- 网页搜索
- ……
- 计划
- 思维链 / 思维树
- 任务分解
- 动作
另外,多个不同功能的智能体可以各司其职,组成多智能体系统,发挥更强大的能力。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Chao Pang的个人主页!